AWS Aurora Cluster Outage
Postmortem
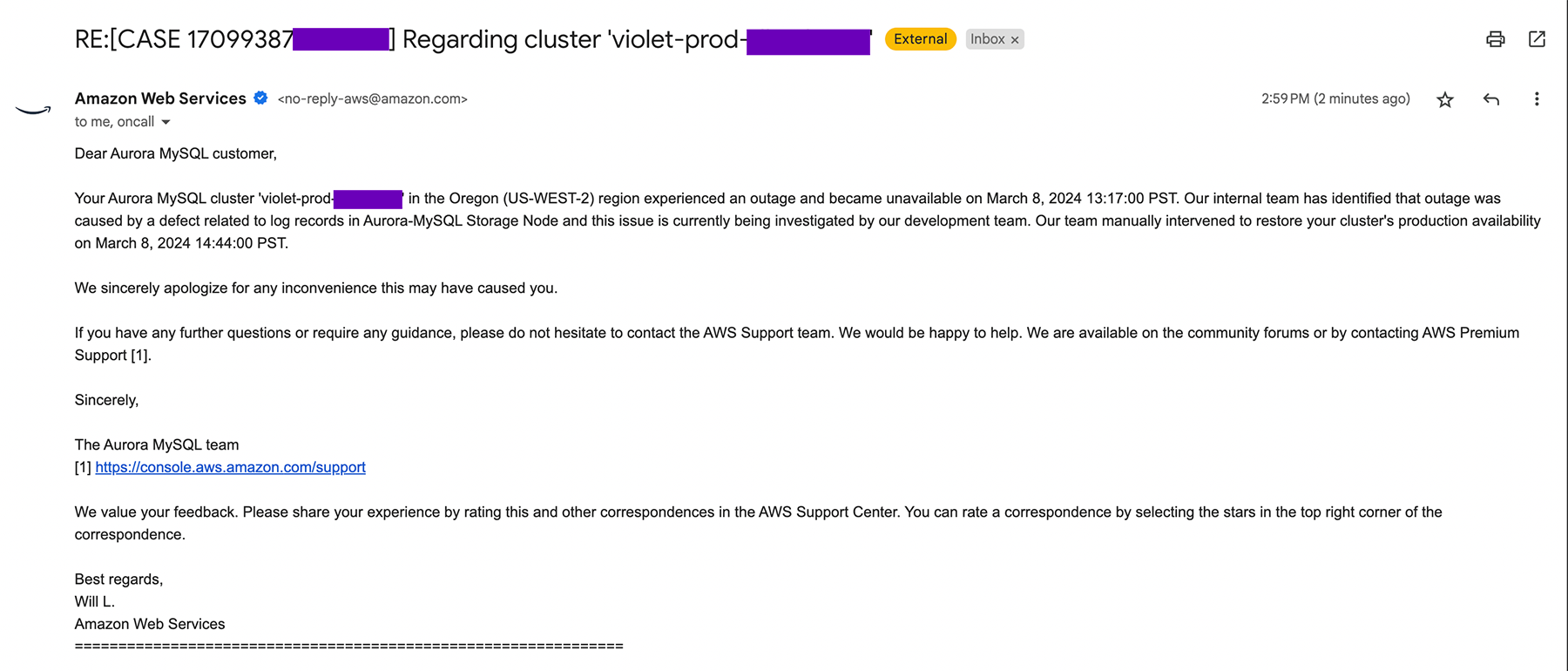
Summary: A critical outage occurred in the Oregon (us-west-2) region of Amazon Web Services (AWS), specifically impacting AWS Aurora database services. This outage resulted in major disruptions and effectively brought down the Violet API. The root cause of the incident was identified as a defect related to log records in Aurora-MySQL Storage Node, which led to the shutdown of Aurora clusters and prevented a quick recovery. This postmortem aims to provide a comprehensive analysis of the outage, lessons learned, and actions taken to prevent similar incidents in the future.
Incident Timeline:
- 2024-03-08 13:17:00 PST: The incident commenced when abnormal performance metrics were observed in the AWS Aurora database infrastructure within the Oregon (us-west-2) region.
- 2024-03-08 13:24:49 PST: The first automated alert was sent to Violet’s alarm system.
- 2024-03-08 13:28:00 PST: Initial investigation into the outage began. The full scope was not immediately recognized and it was thought that an analytics tool had exceeded its connection pool. This tool was immediately shut down.
- 2024-03-08 13:47:00 PST: Realizing the scope of the outage an incident was added to the status.violet.io.
- 2024-03-08 14:01:00 PST: Not yet aware that this was an AWS issue and that AWS was attempting to intervene we manually initiated a reboot of the RDS cluster in an attempt to bring our cluster back online.
- 2024-03-08 14:11:00 PST: All Violet service pods were scaled down to ensure that the cluster would not be overwhelmed when it came back online.
- 2024-03-08 14:12:00 PST: We discovered that maintenance was being applied to our cluster and that it was in crash loop. Still no communication from AWS at this time.
- 2024-03-08 14:29:00 PST: Incident report on status.violet.io was updated to communicate the cluster maintenance issue. At this point we were still waiting for the cluster to recover from the crash loop and attempting to contact AWS for assistance. Spinning up a new DB from the latest snapshot was considered as it was still not clear if our cluster would recover. Still no communication from AWS.
- 2024-03-08 14:39:00 PST: Cluster recovers from the crash loop and the cluster was restarted. AWS began applying patches.
- 2024-03-08 14:44:00 PST: Violet begins spinning up the service pods to restore the API.
- 2024-03-08 14:54:00 PST: All pods are running and the Violet API and Violet dashboards are restored. Still no communication from AWS.
- 2024-03-08 14:54:00 PST: Incident report on status.violet.io is updated to a status of Monitoring.
- 2024-03-08 14:59:00 PST: AWS notified Violet of the outage and its cause. Incident report on status.violet.io is updated to resolved.
Root Cause Analysis: The root cause of the outage was attributed to defect related to log records in Aurora-MySQL Storage Node. As of the time of writing this the AWS development team is still investigating this.
Impact: The outage had significant impacts on the entire Violet system, including:
- Production Checkout and Relay services were unreachable.
- Violet Channel and Merchant Dashboards were unreachable.
- Violet Connect was unreachable.
Lessons Learned:
- Enhanced Monitoring: The first critical alert was sent 8 minutes after AWS stated the outage began.
- Redundancy and Failover: Improved redundancy of the cluster is required.
- Communication Strategy: Improve time to when incident is reported on status.violet.io.
Mitigation Measures:
- Enhanced Monitoring: Implement additional monitoring tools and alerting mechanisms to detect outages sooner.
- Redundancy and Failover: Review and enhance redundancy and failover strategies to improve the resilience and availability of database clusters.
- Communication Improvements: Violet will enhance its communication protocols and procedures to ensure that channels are notified of any issues as quickly as possible.
- Training and Education: Provide additional members of the Violet team with the tools and training to investigate and communicate outages when they occur.
Actions:
- Violet will resync all external products that were modified during the window of the outage.
- Violet will resync the external orders that originated through Violet and were modified during the window of the outage.
Conclusion: This database outage underscored the importance of robust incident response, proactive monitoring, and preventive measures to ensure the reliability and availability of Violets services. By conducting a thorough postmortem analysis, implementing lessons learned, and continuously improving monitoring and mitigation measures, Violet aims to enhance the resilience of its system to better serve our channels and merchants in the future.